前言
在windows系统中,镜像校验工具常被用于自诊断。比如说怀疑系统文件损坏时,就可以使用DISM、sfc等工具寻找系统文件的错误,并且自动修复。比如常见的命令有:
sfc /scannow这个命令需要在具有管理员权限的终端中使用,可以使用win+X快捷键快速找到。
然而可能看到这样的提示:
windows资源保护找到了损坏文件但无法修复其中某些文件。CBS.Log windir\Logs\CBS\CBS.log 中有详细信息。
这可太不好了!通过查看日志,发现这个无法修复的文件,居然是一张桌面壁纸图片?!这个命令的原理是对比文件的哈希校验值,就像对比人的指纹。一旦发现校验值不对,就会认为这是一个损坏的文件。而这种情况,就说明这个壁纸被篡改了,和镜像中记录的合法哈希校验值对不上号了,并且无法修复,这是怎么回事呢?
联想注入壁纸
在目录 C:\Windows\Web\Screen\ 下,可以看到六张图片,分别是img100到img105. 其中,这个img105.jpg就是被记录为无法修复的图片。查阅了一些资料后发现,这里存放的是windows默认的锁屏壁纸存储路径。
而联想预装的电脑管家、壁纸等软件,会修改这里的文件,达到修改锁屏壁纸的目的!这就是罪魁祸首!所以正是这些软件修改了系统文件,导致自检无法通过。
然而,删除这些软件,它们可能不会把修改的文件改回去,这就导致这个文件一直校验出错;我遇到的情况是,它把文件改回了纯蓝色的图片,但是依然无法通过校验!

解决方法
其实解决方法很简单:找一台正常的好电脑,把文件复制过来,覆盖旧文件!就完事!
这个是一个正常的、可以通过校验的正常原文件:

如果遇到相同困扰的小朋友,可以从这里下载这个文件替换即可。这个文件的SHA256哈希码是:
67467B1E0D9A9C4B8CC81EADBDB5E978A11F898A8DA2D661A5C00A62D3A8CC0D如果下载到的校验码和这个不一致,则可能是下载了压缩后的图片。正确的下载方式是,右键这个图片,在新窗口中查看,然后保存这个图片。
进阶解决方法
然而,Windows是不断更新的,这意味着“正确的文件”实际上也在不断变化。
比如,现在img105的图片是本文章的这张蓝色图(SHA256哈希码是67467B1E0D9……这一串)。但是将来这个文件可能被更新,那么预期正确的哈希码就会是一个新的不一样的值(比如说ABCDEFG……)。此时下载本文章的这个文件,覆盖损坏的img105图片文件后,sfc扫描解析到的哈希码就是旧版本文件的哈希值(67467B1E0D9……这一串),和预期的(比如说ABCDEFG……)不一样,就仍然会提示文件损坏。
所以,推荐先检查 CBS.Log 中预期正确的哈希码,看看是不是67467B1E0D9……这一串。
如果不是的话,解决方法也很简单,参照我之前提到的,找一个正确镜像版本的图片复制过来,就完事!
在 Windows设置 -> 系统 -> 系统信息 中可以看到系统镜像的版本。比如我的规格是:Windows 11 专业版,版本号是24H2.
那么,就可以在各种Windows镜像发布平台(比如说MSDN之类的,这里不推荐具体的镜像站了)找到自己版本的镜像,下载下来后,将ISO镜像中的这个正常文件复制过来即可;当然,更方便的是借用小伙伴的电脑,直接把他电脑里面的正常文件复制过来即可。
追根溯源
可是,上面两张图片明明看上去是一样的,为什么一个可以通过校验,另一个就不行呢?
检查文件属性
可以检查一下正常原文件的属性,如下:
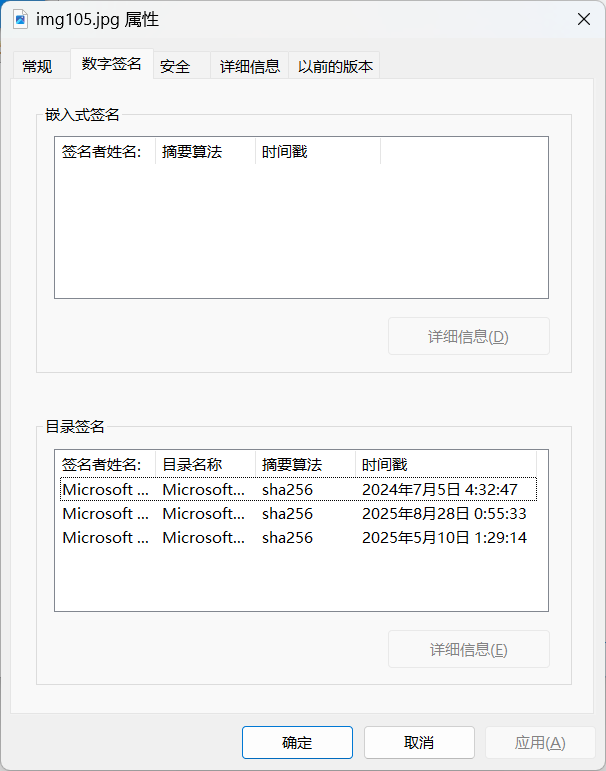
可以发现这个好的原文件是有数字签名的,然而这个坏文件则没有。那么,什么是目录签名呢?这里引用微软文档中找到的解释:
数字签名目录文件 (.cat) 可用作任意文件集合的数字签名。 目录文件包含加密哈希或 指纹的集合。 每个指纹对应于集合中包含的文件。即插即用 (PnP) 设备安装会将驱动程序包的签名目录文件识别为驱动程序包的数字签名。 目录文件中的每个指纹都对应于驱动程序包安装的文件。 无论预期的操作系统如何,加密技术都用于对目录文件进行数字签名。
感觉也没明白这是个啥……我感觉像是系统安装了一些类似证书的东西,然后记录了一些哈希码(指纹)——这些哈希码就是正常系统文件的哈希码。所以,当发现这个文件的哈希码与集合中某个记录的指纹一致时,也就意味着这个文件符合通过了该目录签名的校验,就确信了这个文件是可信的。
校验哈希码
可以在windows使用powershell,校验这个文件的哈希码。注意,cmd不行,不支持。这个命令有点怪,居然是被括号包住的?没错,确实:
(Get-FileHash 'C:\Windows\Web\Screen\img105.jpg' -Algorithm SHA256).Hash正常原文件的输出是:
67467B1E0D9A9C4B8CC81EADBDB5E978A11F898A8DA2D661A5C00A62D3A8CC0D损坏文件的输出是:
C46179323CBB37B3D66E4F86F4107F8A4AA64C4A3AF3903D29023B8A495C6F76两个文件的SHA256哈希校验码不一致!
检查二进制内容
有没有可能,虽然两个文件看上去一致,但是其实二进制内容不一致?写一个简单的python脚本验证一下:
import os
def hex_dump(input_file, output_file):
"""
将输入文件以二进制格式读取,并将每个字节的 HEX 编码写入输出文件。
每行包含 16 个字节,字节之间用空格分隔。
:param input_file: 输入文件的路径
:param output_file: 输出文件的路径
"""
try:
# 打开输入文件(以二进制模式读取)
with open(input_file, 'rb') as f_in:
# 打开输出文件(以写入模式)
with open(output_file, 'w') as f_out:
# 每次读取 16 个字节
chunk = f_in.read(16)
while chunk:
# 将每个字节转换为两位的 HEX 字符串
hex_values = [f"{byte:02X}" for byte in chunk]
# 确保每行有 16 个字节,不足的部分用空格补齐
hex_line = " ".join(hex_values).ljust(16 * 3 - 1)
# 写入输出文件
f_out.write(hex_line + '\n')
# 继续读取下一块
chunk = f_in.read(16)
print(f"HEX 转换完成!结果已保存到 {output_file}")
except FileNotFoundError:
print(f"错误:文件 {input_file} 未找到,请检查路径是否正确。")
except Exception as e:
print(f"发生错误:{e}")
# 示例用法
if __name__ == "__main__":
filename = "img105-ok.jpg"
input_path = f"./{filename}"
output_path = f"./dump_hex_file/{filename}.txt"
# 调用函数
hex_dump(input_path, output_path)
这段代码可以把指定的文件转化为格式化的、以十六进制(HEX)表示的字符串,存储到txt文件中;接着,就可以使用vscode等工具做对比了。结果,真的发现有两个字节不一致!
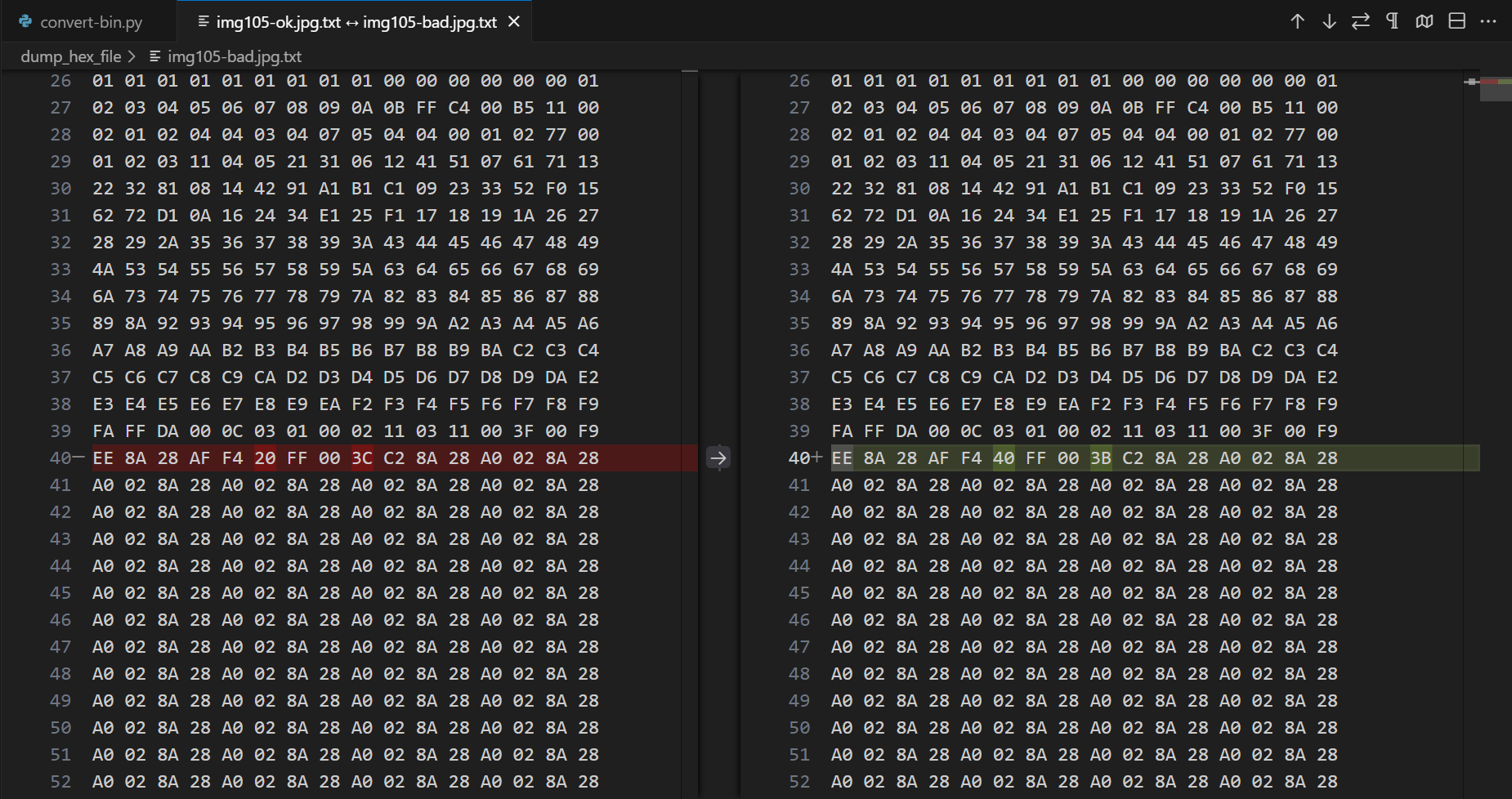
坑爹的联想!居然使用损坏的文件,有两字节不一致!至此,问题解决!
不过,有人知道这两个字节对应的实际含义吗?看这个长度,和位置,可能是一些不影响图片显示的冗余信息?具体还是需要更专业的考证了,这里目前探究不出来了。
Comments 2 条评论
成功替换文件校验哈希值也正确,但是执行 sfc /scannow还是提示损坏文件,打开CBS看还是提示哈希值错误,这怎么办呢
@1106424907 可能是我们镜像版本不一样,导致sfc认为的正确文件不同。
比如我这边镜像校准要求文件的哈希码是67467B1E0D9A9…这一串,是旧版本的文件;你那边的镜像是新版本,要求是另一个哈希码。
CBS里面会记录预期正确的哈希码,你可以看看是不是67467B1E0D9A9…这一串。如果不是,那可能需要你找一个匹配版本的镜像,把那里的img105复制到你电脑上。